Dynamic Adversarial Reinforcement Learning for Robust Multimodal Large Language Models
Abstract
Despite their impressive capabilities, Multimodal Large Language Models (MLLMs) exhibit perceptual fragility when confronted with visually complex scenes. This weakness stems from a reliance on finite training datasets, which are prohibitively expensive to scale and impose a ceiling on model robustness.
We introduce AOT-SFT, a large-scale adversarial dataset for bootstrapping MLLM robustness. Building on this, we propose AOT (Adversarial Opponent Training), a self-play framework that forges MLLM robustness by creating its own training data. Our method orchestrates a co-evolution between an image-editing Attacker and a Defender MLLM, where the Attacker generates a diverse and dynamic curriculum of image manipulations, forcing the Defender to adapt and improve.
Extensive experiments demonstrate that AOT enhances the Defender's perceptual robustness and reduces hallucinations, establishing a scalable paradigm for training more reliable MLLMs.
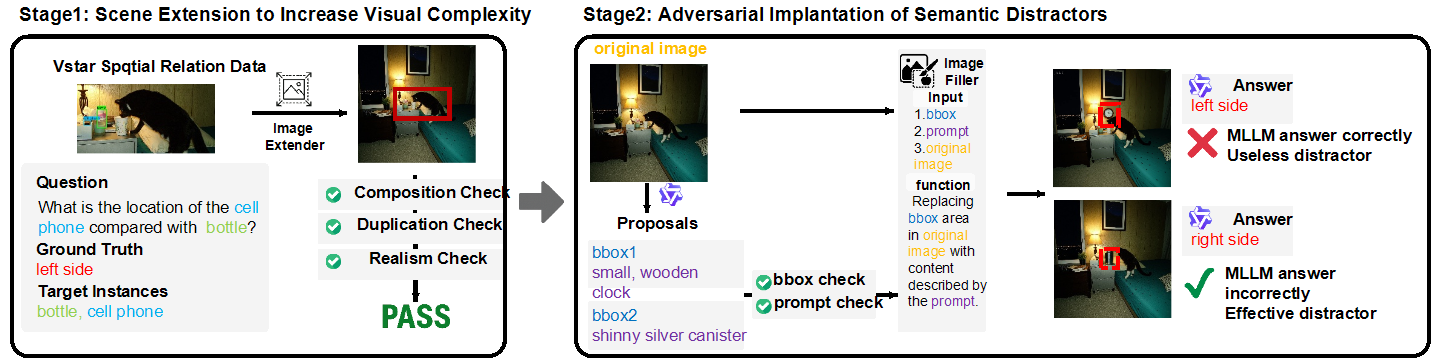
Two-Stage Pipeline for AOT-SFT
We designed a dedicated two-stage data generation pipeline to create a high-quality dataset for initial training. Stage 1 involves Scene Extension to increase visual complexity via outpainting, followed by rigorous quality checks. Stage 2 involves Adversarial Implantation of Semantic Distractors, ensuring objects do not overlap and the distractors are effective.
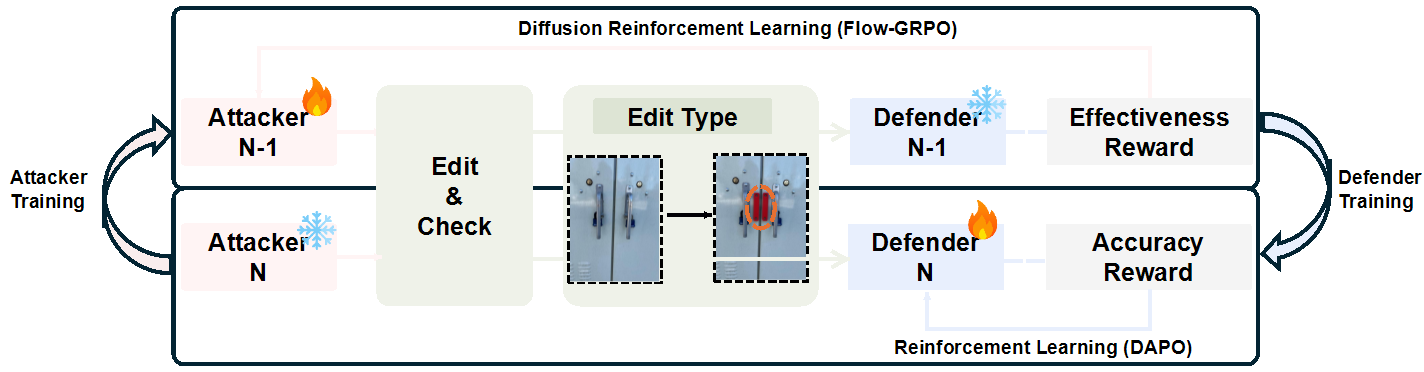
Iterative Attacker-Defender Co-evolution
Our iterative, generative adversarial framework features a co-evolutionary dynamic between an Attacker (M_atk) (an image editing model) and a Defender (M_def) (the MLLM whose perception we aim to strengthen). The active attacker is refined using Flow-GRPO to generate adversarial edits, and the newly updated attacker generates challenging examples to train the active defender via DAPO.
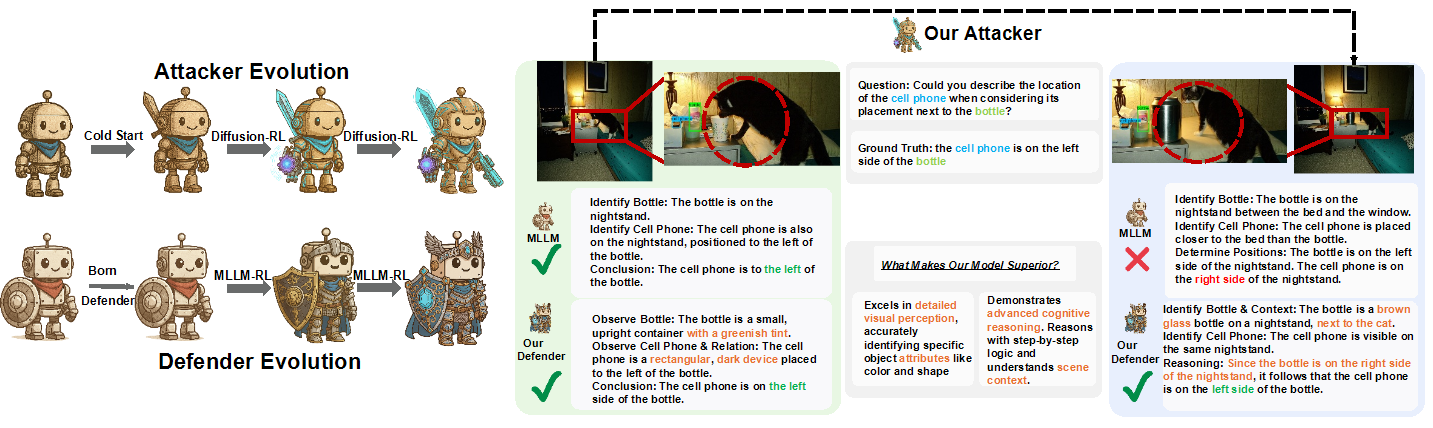
Emergent Attacker Strategies
A key outcome of our framework is the attacker's ability to autonomously discover a diverse repertoire of attack strategies. These emergent tactics include imperceptible pixel-level perturbations, object replacement, object removal, object addition, and hybrid attacks, preventing the defender from overfitting to a single threat type.

BibTeX
@misc{bao2026deceive,
title={Dynamic Adversarial Reinforcement Learning for Robust Multimodal Large Language Models},
author={Yicheng Bao and Xuhong Wang and Qiaosheng Zhang and Chaochao Lu and Xia Hu and Xin Tan},
year={2026},
eprint={2602.22227},
archivePrefix={arXiv},
primaryClass={cs.CV}
}